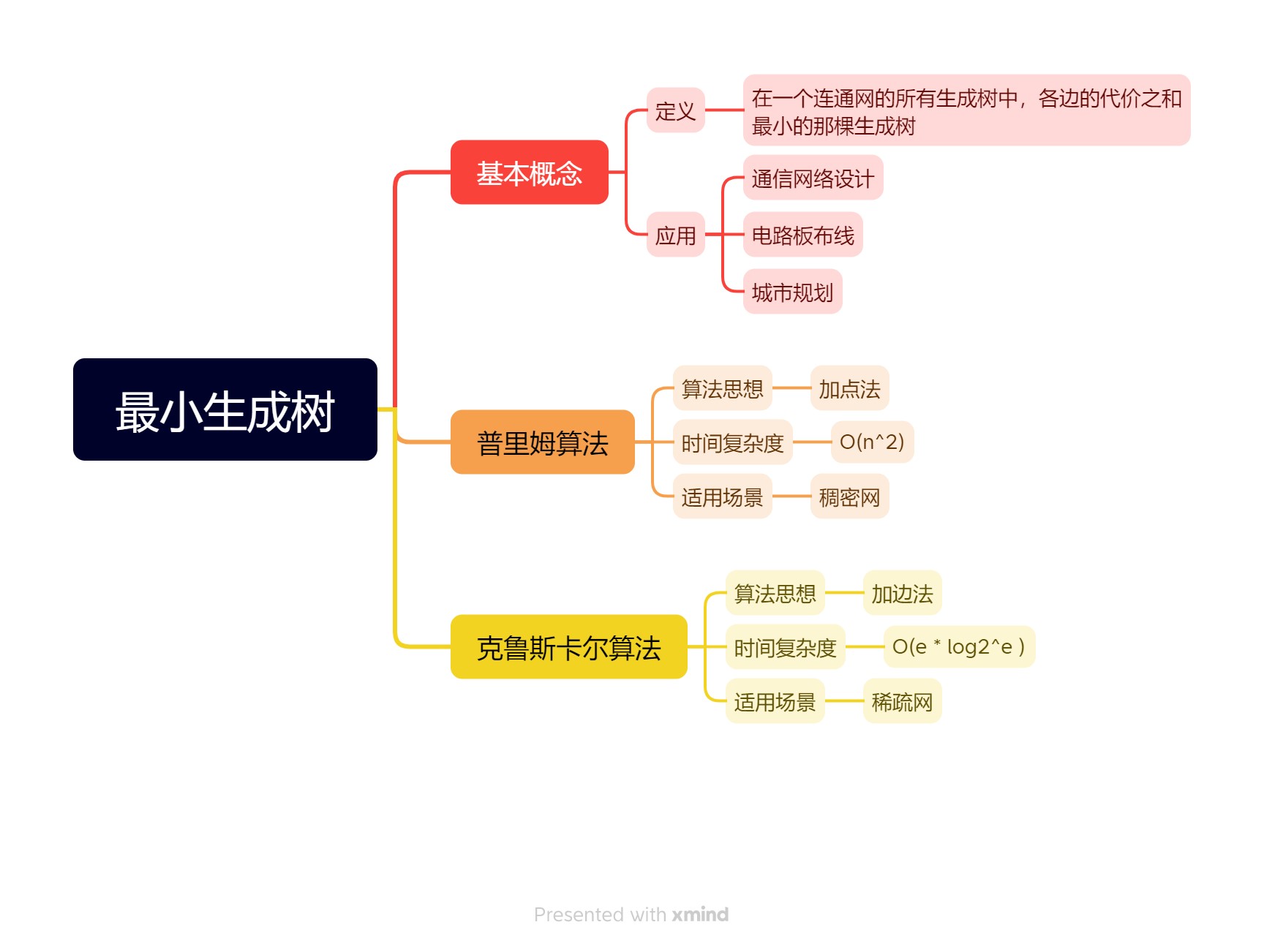
数据结构:最小生成树
最小生成树是图论中的一个重要概念,它在许多实际应用中都扮演着重要角色,比如通信网络设计、电路板布线、城市规划等。在实际应用中,最小生成树的构建可以帮助优化网络设计、资源分配等问题。通过选择最小生成树,可以在保持网络连通性的前提下,使得整体成本最小化。因此,了解最小生成树的概念和算法对于解决实际问题具有重要意义。
一、基本概念
在连通网的所有生成树中,各边的代价之和最小的那棵生成树称为该连通网的最小代价生成树(Minimum Cost Spanning Tree),简称为最小生成树。
假设要在n个城市之间建立通信联络网,则连通n个城市只需要n−1条线路。这时,自然会考虑这样一个问题,如何在最节省经费的前提下建立这个通信网。每两个城市之间都可设置一条线路,相应地都要付出一定的经济代价。n个城市之间,最多可能设置n(n−1)/2条线路,那么,如何在这些可能的线路中选择n−1条,以使总的耗费最少呢?
在计算机系统中,可以用连通网来表示n个城市,以及n个城市间可能的通信线路,其中网的顶点表示城市,边表示两城市之间的线路,赋予边的权值表示相应的代价。对于n个顶点的连通网可以建立许多不同的生成树,每一棵生成树都可以是一个通信网。最合理的通信网应该是代价之和最小的生成树。
构造最小生成树有多种算法,其中多数算法利用了最小生成树的MST性质:假设G=(V, E)是一个连通网,U是顶点集V的一个非空子集。若(u, v)是一条具有最小权值(代价)的边,其中,则必存在一棵包含边(u, v)的最小生成树。
最小生成树的MST性质可用反证法来证明。假设连通网G的任何一棵最小生成树都不包含(u, v)。设T是连通网的一棵最小生成树,当将边(u, v)加入到T中时,由生成树的定义,T中必存在一条包含(u, v)的回路。另一方面,由于T是生成树,则在T上必存在另一条边(u’, v’),其中,且u和u’之间、v和v’之间均有路径。删去边(u’, v’),便可消除上述回路,同时得到另一棵生成树T’。因为(u, v)的权值不高于(u’, v’),则T’的权值亦不高于T,即T’是包含(u, v)的一棵最小生成树。由此和假设矛盾。
普里姆(Prim)算法和克鲁斯卡尔(Kruskal)算法是两个最常用的、利用MST性质构造最小生成树的算法。接下来,详细介绍这两种算法。
二、普里姆算法
2.1、算法思想
假设G=(V, E)是一个具有n个顶点的连通网,T=(U, TE)是G的最小生成树。
- 初始情况下,U和TE均为空,即U={},TE={}。
- 从V中任取一个顶点(假定为),将它并入U中,此时。
- 从一端已在U中,另一端仍在U外的所有边中,找一条权值最小的边(u, v),其中,将该边并入TE,同时将v并入U。
- 重复上一步,直至U=V为止。此时,TE中必有n-1条边,则T是G的最小生成树。
如下图,是按普里姆算法,对连通网G构造最小生成树的过程。
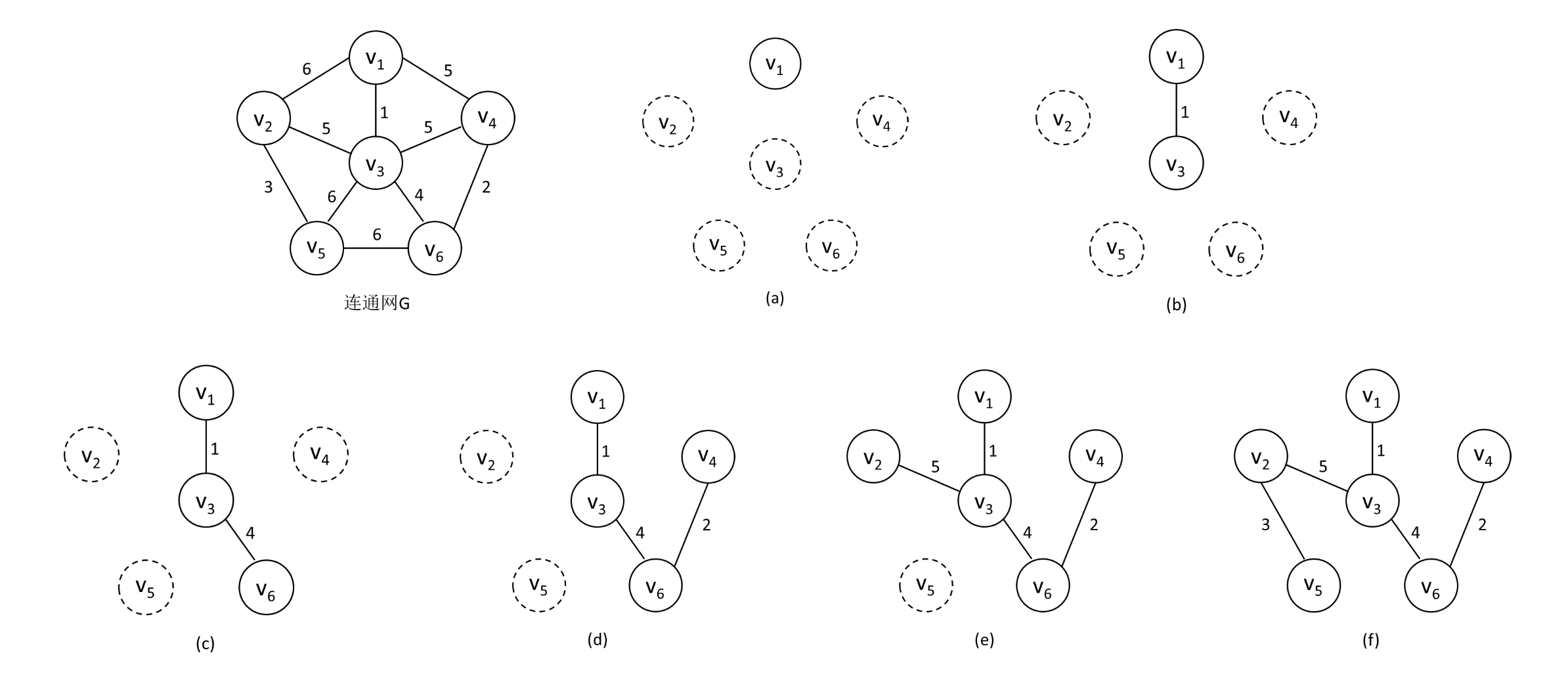
最开始,。然后,从一端已在U中,另一端仍在U外的所有边中,找到一条权值最小的边并入TE,同时将并入U,此时。接着,继续从一端已在U中,另一端仍在U外的所有边中,找到一条权值最小的边并入TE,同时将并入U,此时;依此类推,直到U=V。
可以看出,普里姆算法的执行过程,是一个逐步增加U中顶点的过程,因此可称该算法为“加点法”。在选择最小边时,如果有多条权值相同的边可选,此时任选其一即可。
2.2、算法步骤
假设连通网G以邻接矩阵形式存储,从顶点u出发构造G的最小生成树T,要求输出T的各条边。
在实现普里姆算法时,需附设一个辅助数组closedge,记录从U到V−U具有最小权值的边。对每个顶点,在辅助数组中存在一个相应分量closedge[i-1],每个分量由两个域组成,它们分别是lowcost和adjvex,其中lowcost存储最小边上的权值,adjvex存储最小边在U中的那个顶点。也即,其中cost(u, v)表示赋于边(u, v)的权。
在C语言中,辅助数组closedge的定义如下:
1 | |
普里姆算法的步骤具体如下:
- 将初始顶点u并入U中,对其余的每个顶点,将closedge[j]初始化为到u的边信息。
- 循环n-1次,选择其余的n-1个顶点,生成n-1条边:
- 从closedge中选出权值最小的边closedge[k],输出此边;
- 将k并入U中;
- 更新closedge信息 ,由于新顶点的加入,从U到V-U会有新边,如果新边的权值比closedge[j].lowcost小,则将closedge[j]更新为新边。
2.3、算法描述
1 | |
下表是利用普里姆算法,对前面的连通网G从顶点开始,构造最小生成树时各量的变化。
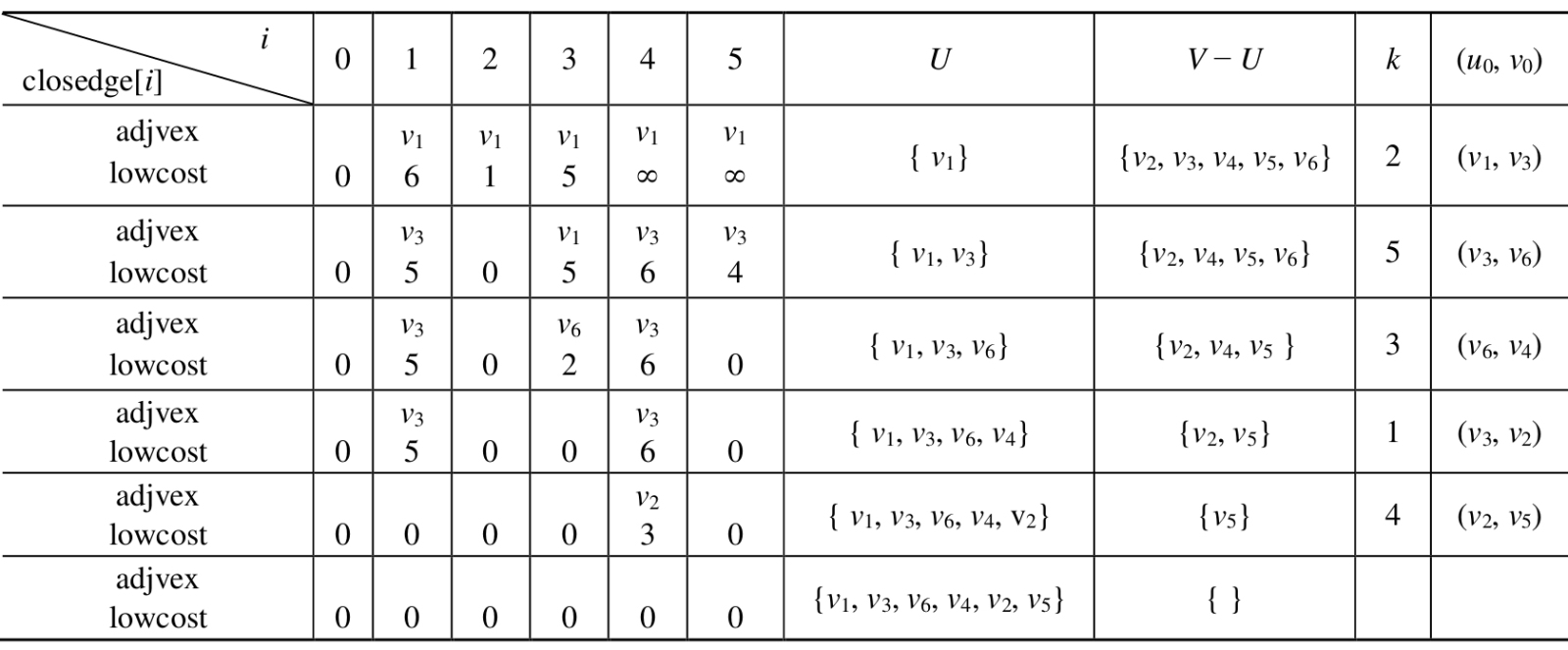
最开始,从U到V−U具有最小权值的边,是从依附于顶点的各条边中,找到一条权值最小的边,作为生成树中的第一条边,同时将顶点并入集合U中。然后修改辅助数组中的值,首先将closedge[2].lowcost改为0,表明顶点已并入U。又由于边的权值小于closedge[1].lowcost,则需修改closedge[1]为边及其权值。同理修改closedge[4]和closedge[5]。依次类推,直到U=V。
2.4、算法分析
假设网中有n个顶点,则第一个进行初始化的循环语句的频度为n,第二个循环语句的频度为n−1。其中,第二个循环语句中有两个内循环:其一是在closedge[v].lowcost中求最小值,其频度为n−1;其二是重新选出具有最小权值的边,其频度为n。由此,普里姆算法的时间复杂度为,与网中的边数无关,因此适用于求稠密网的最小生成树。
三、克鲁斯卡尔算法
3.1、构造过程
假设G=(V, E)是一个具有n个顶点的连通网,T=(U, TE)是G的最小生成树。
- 初始状态下,U=V,TG={},即T的初始状态是只含有n个顶点而无边的非连通图T=(V, {})。
- 将图G中的边按权值从小到大排序。
- 依次选取E中的边,若选取的边使生成树T不形成回路,则把它并入TE中,否则将其舍弃。
- 重复上一步,直到TE中包含n-1条边为止,此时的T即为最小生成树。
如下图,是按克鲁斯卡尔算法,对连通网G构造最小生成树的过程。
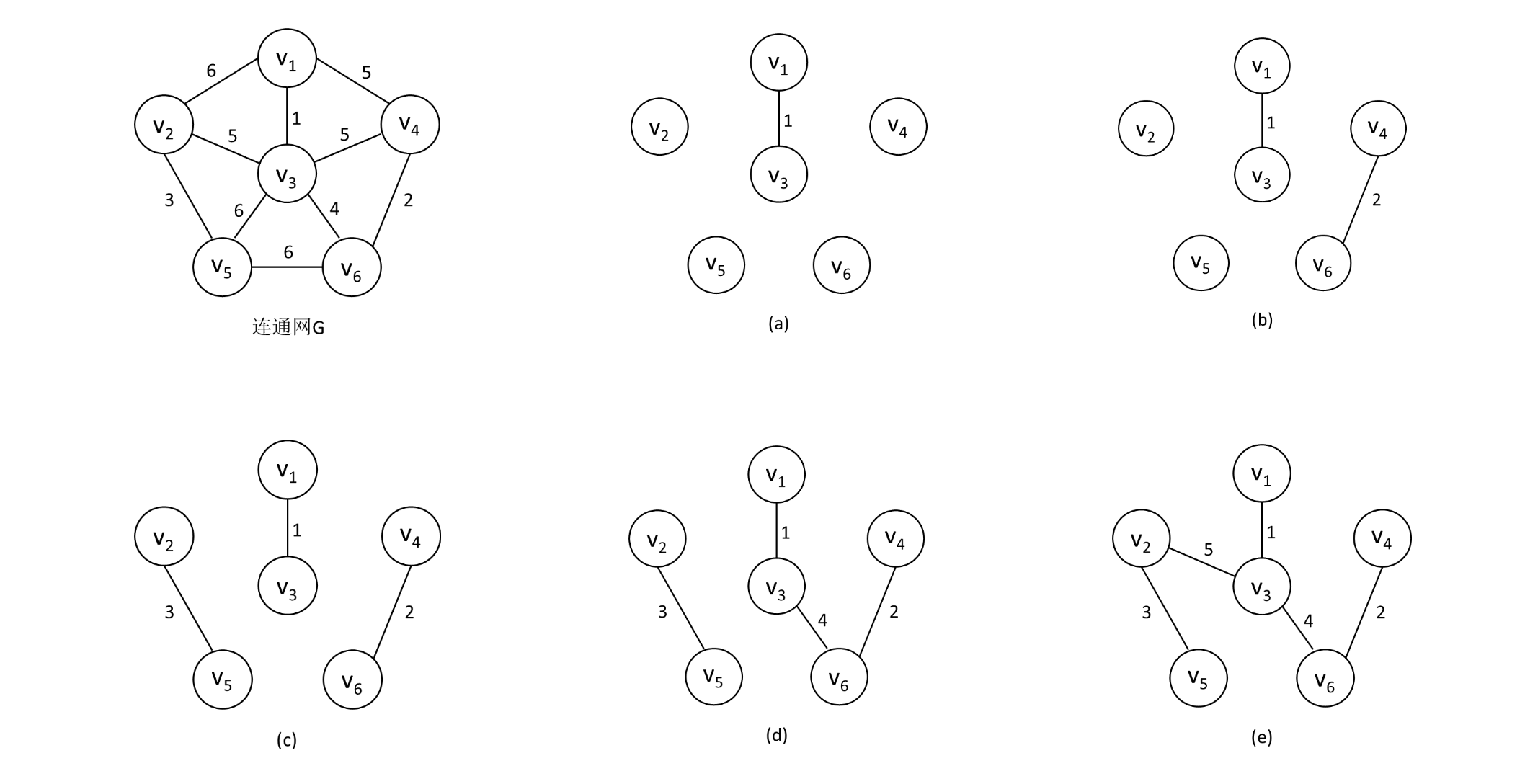
权值分别为1、2、3、4的4条边由于满足上述条件,则先后被加入到T中;权值为5的两条边和被舍去,因为它们依附的两顶点在同一连通分量上,它们若加入T 中,则会使T产生回路,而另一条权值为5的边连接两个连通分量,则可加入T 。由此,构造成一棵最小生成树。
可以看出,克鲁斯卡尔算法逐步增加生成树的边,与普里姆算法相比,可称为“加边法”。与普里姆算法一样,每次选择最小边时,可能有多条同样权值的边可选,可以任选其一。
3.2、算法实现
克鲁斯卡尔算法的实现需要引入以下辅助的数据结构:
- 结构体数组Edge:存储边的信息,包括边的两个顶点和权值。
- 数组Vexset,标识各个顶点所属的连通分量。对每个顶点,在辅助数组中存在一个相应元素Vexset[i]表示该顶点所在的连通分量。初始时Vexset[i]=i,表示自成一个连通分量。
在C语言中,上述辅助数据结构的定义如下:
1 | |
克鲁斯卡尔算法的步骤为:
- 将数组Edge中的元素按权值从小到大排序。
- 依次查看数组Edge中的边,循环执行以下操作:
- 依次从排好序的数组Edge中选出一条边;
- 在数组Vexset中分别查找和所在的连通分量和,并进行判断:
- 如果和不等,表明所选的两个顶点分属不同的连通分量,输出此边,并合并和两个连通分量;
- 如果和相等,表明所选的两个顶点属于同一个连通分量,舍去此边而选择下一条权值最小的边。
相应的算法描述为:
1 | |
若以“堆”来存放网中的边进行堆排序,对于包含e条边的网,上述算法排序时间是。在for循环中最耗时的操作是合并两个不同的连通分量,只要采取合适的数据结构,可以证明其执行时间为,因此整个for循环的执行时间是。由此,克鲁斯卡尔算法的时间复杂度为,与网中的边数有关,与普里姆算法相比,克鲁斯卡尔算法更适合于求稀疏网的最小生成树。
四、小结
构造最小生成树有普里姆算法和克鲁斯卡尔算法,两者都能达到同一目的。前者算法思想的核心是归并点,时间复杂度是,适用于稠密网;后者是归并边,时间复杂度是,适用于稀疏网。