在实际应用中,最短路径算法被广泛应用于网络路由、交通规划、物流配送等领域。例如,在物流管理中,通过优化整个物流体系,实现最短路径、最低成本的物流管理,可以有效降低物流成本,提高效率。因此,了解最短路径的概念和算法对于解决实际问题具有重要意义。
一、最短路径问题
如果要在计算机上建立一个交通咨询系统,则可以采用图的结构来表示实际的交通网络。如下图所示,图中顶点表示城市,边表示城市间的交通联系。例如,一位旅客要从A城到B城,他希望选择一条中转次数最少的路线。
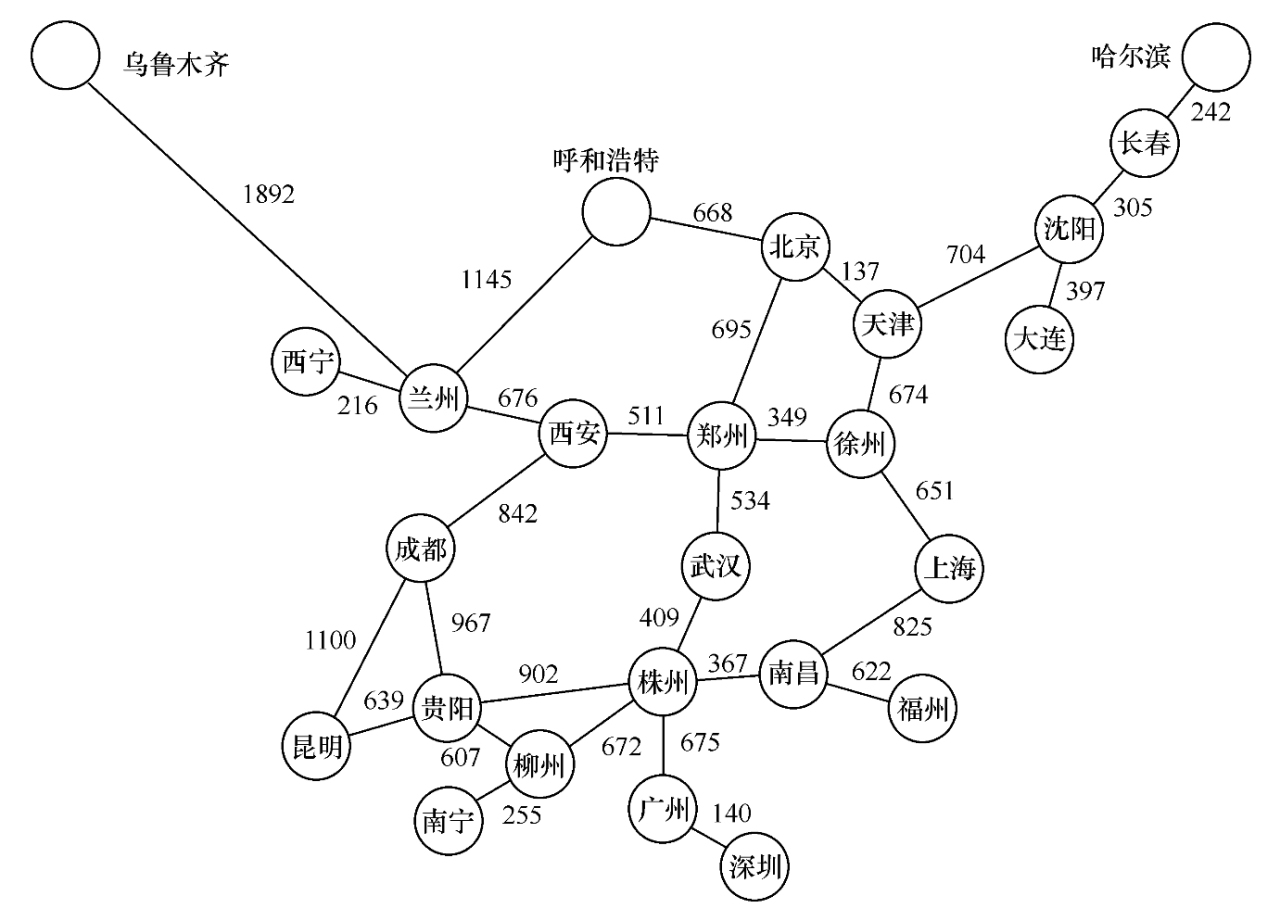
假设图中每一站都需要换车,则这个问题反映到图结构中就是要找一条从顶点A到顶点B所含边的数目最少的路径。只需从顶点A出发对图做广度优先搜索,一旦遇到顶点B就终止。由此所得的广度优先生成树上,从根顶点A到顶点B的路径就是中转次数最少的路径,路径上A与B之间的顶点数就是中转次数。
有时,对于旅客来说,可能更关心的是节省交通费用;而对于司机来说,里程和速度则是他们感兴趣的信息。为了在图上表示有关信息,可对边赋以权,权的值表示两城市间的距离,或途中所需时间,或交通费用等。此时路径长度的度量就不再是路径上边的数目,而是路径上边的权值之和。
考虑到交通图的有向性,例如,汽车的上山和下山,轮船的顺水和逆水,所花费的时间或代价不相同,所以交通网往往是用带权有向网表示。在带权有向网中,习惯上称路径上的第一个顶点为源点(Source),最后一个顶点为终点(Destination)。
最常见的最短路径问题有两种:一种是求从某个源点到其余各顶点的最短路径,另一种是求每一对顶点之间的最短路径。下面,我们将分别讨论这两种最短路径问题。
二、迪杰斯特拉算法
从某个源点到其余各顶点的最短路径,也称单源点最短路径问题。即,给定带权有向图G和源点v0,求从v0到G中其余各顶点的最短路径。迪杰斯特拉(Dijkstra)提出了一个按路径长度递增的次序产生最短路径的算法,因此称为迪杰斯特拉算法。
2.1、求解过程
对于网G=(V, E),迪杰斯特拉算法的求解过程如下:
- 首先,将G中的顶点分成两组:第一组S,为已求出最短路径的终点集合(初始时只包含源点v0);第二组V-S,为尚未求出最短路径的顶点集合(初始时为V−{v0})。
- 然后,按各顶点与v0间最短路径长度递增的次序,逐个将集合V-S中的顶点并入到集合S中。在这个过程中,总保持从v0到集合S中各顶点的路径长度始终不大于到集合V-S中各顶点的路径长度。
这种求解方法能确保是正确的。因为,假设S为已求得最短路径的终点的集合,则可证明:下一条最短路径(设其终点为x)或者是边(v, x),或者是中间只经过S中的顶点而最后到达顶点x的路径。这可用反证法来证明。假设此路径上有一个顶点不在S中,则说明存在一条终点不在S而长度比此路径短的路径。但是,这是不可能的。因为算法是按路径长度递增的次序来产生最短路径的,故长度比此路径短的所有路径均已产生,它们的终点必定在S中,即假设不成立。
例如,下图是一个带权有向图:
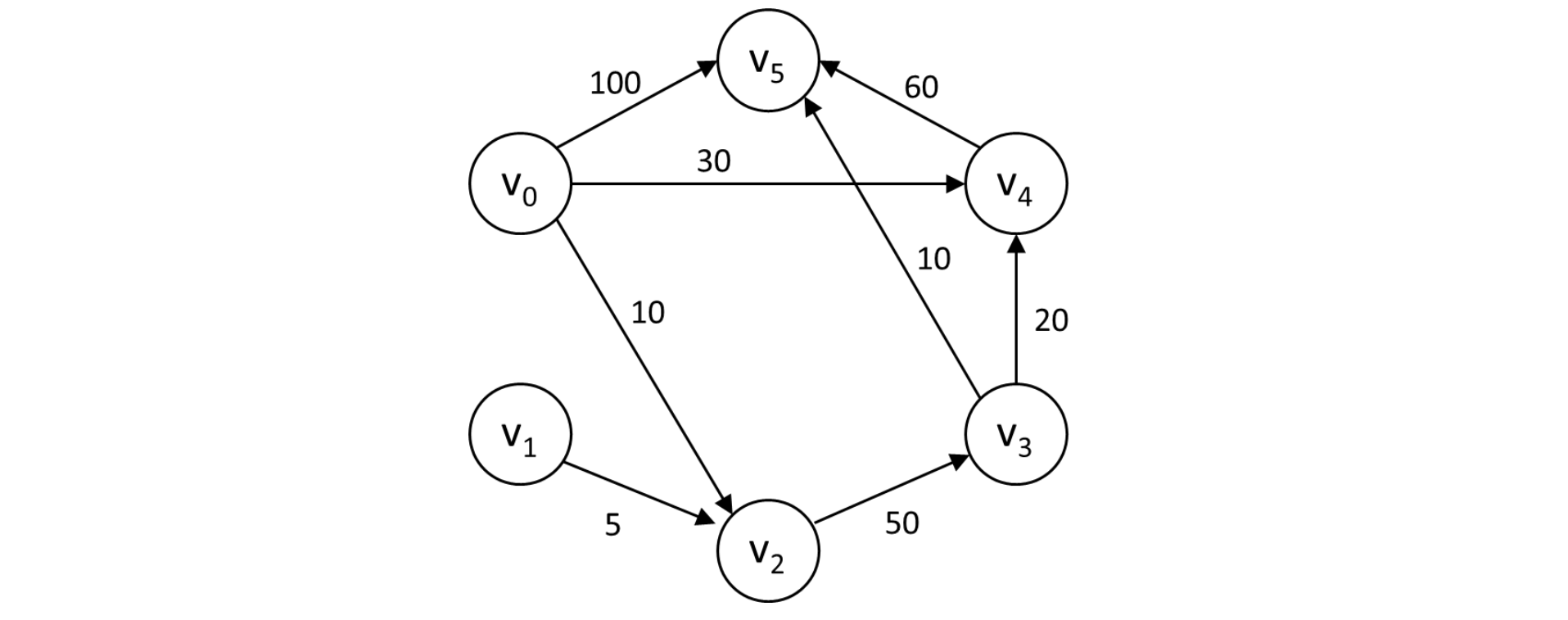
下表是从图中顶点v0到其余各顶点的最短路径:
| 源点 |
终点 |
最短路径 |
路径长度 |
| v0 |
v2 |
(v0,v2) |
10 |
| v0 |
v4 |
(v0,v4) |
30 |
| v0 |
v3 |
(v0,v4,v3) |
50 |
| v0 |
v5 |
(v0,v4,v3,v5) |
60 |
| v0 |
v1 |
无 |
∞ |
根据迪杰斯特拉算法的求解过程,按路径长度递增的次序,首先求出v0到v2的路径(v0,v2),然后依次求得v0到v4的路径(v0,v4),v0到v3的路径(v0,v4,v3),v0到v5的路径(v0,v4,v3,v5),而从v0到v1没有路径。
2.2、算法步骤
假设用带权的邻接矩阵arcs来表示带权有向网G,G.arcs[i][j]表示弧<vi,vj>上的权值。若<vi,vj>不存在,则置G.arcs[i][j]为无穷大。求源点v0到其余各顶点的算法实现要引入以下辅助数据结构:
- 一维数组S[i]:记录从源点v0到终点vi的最短路径是否已被确定,true表示已经确定,false表示尚未确定。
- 一维数组Path[i]:记录从源点v0到终点vi的当前最短路径上vi的直接前驱顶点序号。其初值为:如果从v0到vi有弧,则Path[i]为v0;否则为-1。
- 一维数组D[i]:记录从源点v0到终点vi的当前最短路径长度。其初值为:如果从v0到vi有弧,则D[i]为弧上的权值;否则为无穷大。
显然,长度最短的一条最短路径必为(v0,vk),其满足以下条件:
D[k]=Min{D[i]∣vi∈V−S}
当求得从顶点v0到vk的最短路径后,将vk加入到第一组顶点集S中。每当加入一个新的顶点到顶点集S,对第二组剩余的各个顶点而言,多了一个“中转”顶点,从而多了一条“中转”路径,所以要对第二组剩余的各个顶点的最短路径长度进行更新。例如,原来v0到vi的最短路径长度为D[i],加进vk之后,以vk作为中间顶点的“中转”路径长度为:D[k]+G.arcs[k][i],若D[k]+G.arcs[k][i]<D[i],则用D[k]+G.arcs[k][i]取代D[i]。更新后,再选择数组D中值最小的顶点加入到第一组顶点集S中,如此进行下去,直到图中所有顶点都加入到第一组顶点集S中为止。
迪杰斯特拉算法的步骤为:
- 初始化:
- 将源点v0加到S中,即S[v0]=true;
- 将v0到各个终点的最短路径长度初始化为权值,即D[i]=G.arcs[v0][vi],(vi∈V−S);
- 如果v0和顶点vi之间有弧,则将vi的前驱置为v0,即Path[i]=v0,否则Path[i]=−1。
- 循环n-1次,执行以下操作:
- 选择下一条最短路径的终点vk,使得:D[k]=Min{D[i]∣vi∈V−S}
- 将vk加到S中,即S[vk]=true;
- 更新从v0出发到集合V-S中任一顶点的最短路径的长度,若D[k]+G.arcs[k][i]<D[i],则更新D[i]=D[k]+G.arcs[k][i],同时更改vi的前驱为vk,即Path[i]=k。
2.3、算法描述
迪杰斯特拉算法的C语言描述如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
void ShortestPath(AMGraph G, int v0) {
n=G.vexnum;
for(v=0;v<n;++v) {
S[v]=false;
D[v]=G.arcs[v0][v]
if(D[v]<MaxInt) Path[v]=v0;
else Path[v]=-1;
}
S[v0]=true;
D[v0]=0;
for(i=1;i<n;++i) {
min=MaxInt;
for(w=0;w<n;++w) {
if(!S[w]&&D[w]<min) {
v=w;
min=D[w];
}
}
S[v]=true;
for(w=0;w<n;++w) {
if(!S[w]&&(D[v]+G.arcs[v][w]<D[w])) {
D[w]=D[v]+G.arcs[v][w];
Path[w]=v;
}
}
}
}
|
2.4、示例说明
利用迪杰斯特拉算法,对下图所示的有向网G求解最短路径,给出算法中各参量的初始化结果和求解过程中的变化。
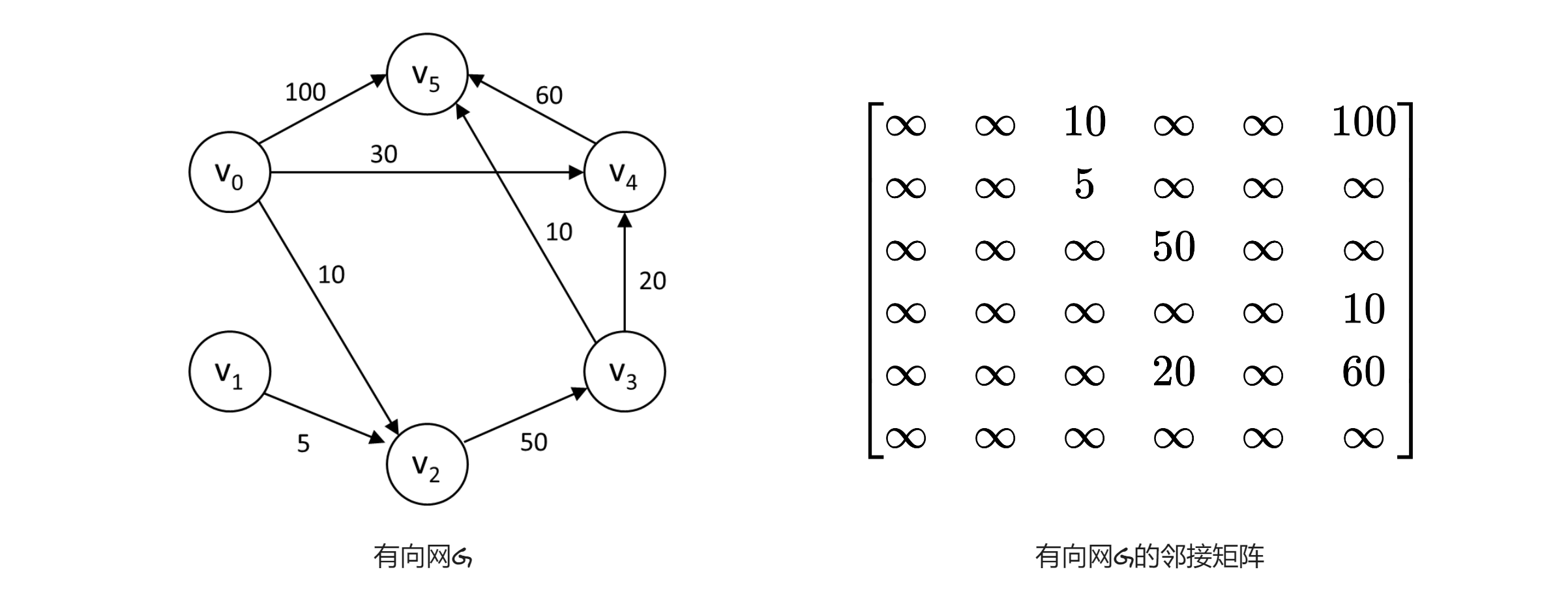
对图中个顶点依次初始化,迪杰斯特拉算法初始化结果,如下表:
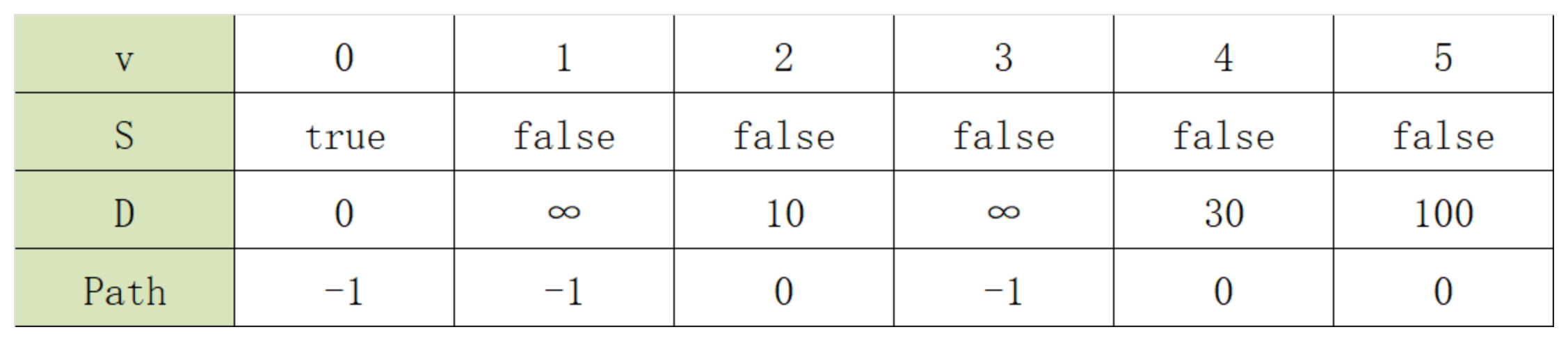
迪杰斯特拉算法求解过程中各参量的变化,如下表
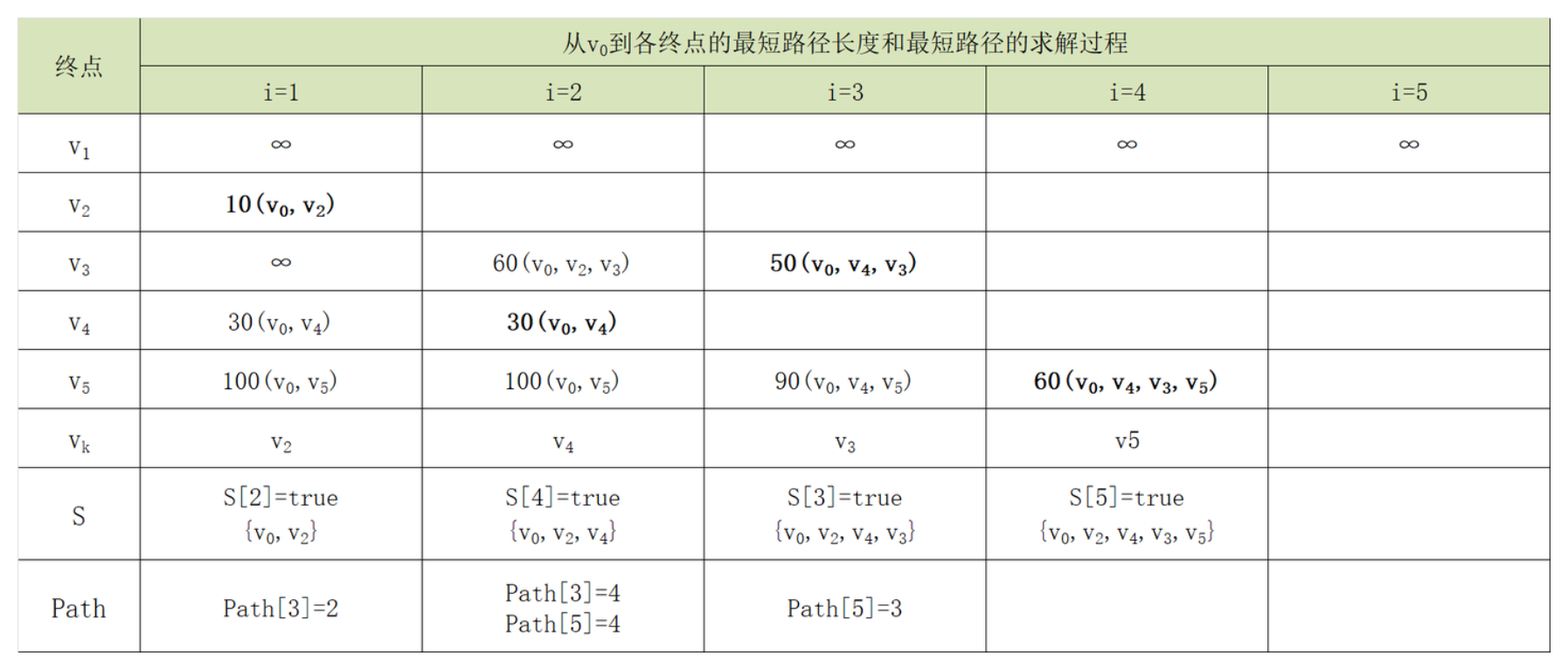
如何从上表读取源点v0到终点vk的最短路径?以顶点v5为例:
1
2
3
| Path[5]=3
Path[3]=4
Path[4]=0
|
反过来排列,得到路径0、4、3、5,这就是源点v0到终点vk的最短路径。
2.5、算法分析
迪杰斯特拉算法的主循环共进行n−1次,每次执行的时间是O(n),所以算法的时间复杂度是O(n2)。
如果用带权的邻接表作为有向图的存储结构,则虽然更新数组D的时间可以减少,但由于在D中找出最短路径的时间不变,所以时间复杂度仍为O(n2)。
在实际应用中,人们可能只希望找到从某个源点出发,到某一个特定终点的最短路径。但是,这个问题和单求源点到其他所有顶点的最短路径一样复杂,也需要利用迪杰斯特拉算法来解决,其时间复杂度仍为O(n2)。
三、弗洛伊德算法
求解每一对顶点之间的最短路径有两种方法:其一是分别以图中的每个顶点为源点共调用n次迪杰斯特拉算法;其二是采用弗洛伊德(Floyd)算法。下面,我们终点讨论弗洛伊德算法。
3.1、算法步骤
弗洛伊德算法仍然使用带权的邻接矩阵arcs来表示有向网G。求从顶点vi到vj的最短路径的算法实现要引入以下辅助的数据结构:
- 二维数组Path[i][j]:记录最短路径上顶点vj的前一顶点的序号。
- 二维数组D[i][j]:记录顶点vi和vj之间的最短路径长度。
弗洛伊德算法的步骤为:
- 初始化vi到vj的最短路径长度,即D[i][j]=G.arcs[i][j];
- 进行n次比较和更新:
- 在vi和vj间加入顶点v0,比较(vi,vj)和(vi,v0,vj)的路径长度,取其中较短者作为vi到vj的中间顶点序号不大于0的最短路径。
- 在vi和vj间加入顶点v1,得到(vi,...,v1)和(v1,...,vj),其中(vi,...,v1)是vi到v1的中间顶点序号不大于0的最短路径,(v1,...,vj)是v1到vj的中间顶点序号不大于0的最短路径,这两条路径已在上一步中求出。比较(vi,...,v1,...,vj)与上一步求出的vi到vj的中间顶点序号不大于0的最短路径,取其中较短者作为vi到vj的中间顶点序号不大于1的最短路径。
- 依次类推,在vi和vj间加入顶点vk,若(vi,...,vk)和(vk,...,vj)分别是从vi到vk和vk到vj的中间顶点序号不大于k-1的最短路径,则将(vi,...,vk,...,vj)和已经得到的从vi到vj且中间顶点序号不大于k-1的最短路径相比较,其长度较短者便是从vi到vj的中间顶点序号不大于k的最短路径。
- 这样,经过n次比较后,最后求得的必是从vi到vj的最短路径。按此方法,可以同时求得各对顶点间的最短路径。
根据上述求解过程,图中所有顶点对(vi,vj)间的最短路径长度对应一个n阶方阵D。在上述n+1步中,D的值不断变化,可对应到一个n阶方阵序列。这个n阶方阵序列可定义为:
D(−1),D(0),D(1),...,D(k),...,D(n−1)
其中,
D(−1)[i][j]=G.arcs[i][j]
D(k)[i][j]=min{D(k−1)[i][j],D(k−1)[i][k]+D(k−1)[k][j]}0≤k≤n−1
显然,D(1)[i][j]是从vi到vj的中间顶点序号不大于1的最短路径的长度;D(k)[i][j]是从vi到vj的中间顶点序号不大于k的最短路径的长度;D(n−1)[i][j]是从vi到vj的最短路径的长度。
3.2、算法描述
弗洛伊德算法的C语言描述如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
void ShortestPath_Floyd(AMGraph G) {
for(i=0;i<G.vexnum;++i) {
for(j=0;j<G.verxnum;++j) {
D[i][j]=G.arcs[i][j];
if(D[i][j]<MaxInt) Path[i][j]=i;
else Path[i][j]=-1;
}
}
for(k=0;k<G.vexnum;++k) {
for(i=0;i<G.vexnum;++i) {
for(j=0;i<G.vexnum;++j) {
if(D[i][k]+D[k][j]<D[i][j]) {
D[i][j]=D[i][k]+D[k][j];
Path[i][j]=Path[k][j];
}
}
}
}
}
|
3.3、示例说明
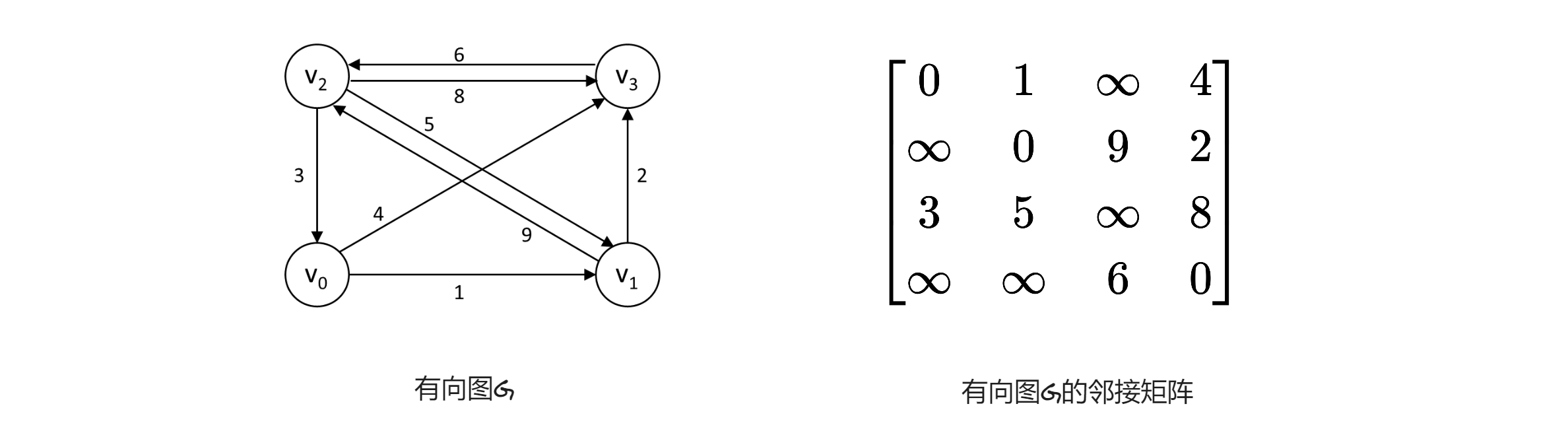
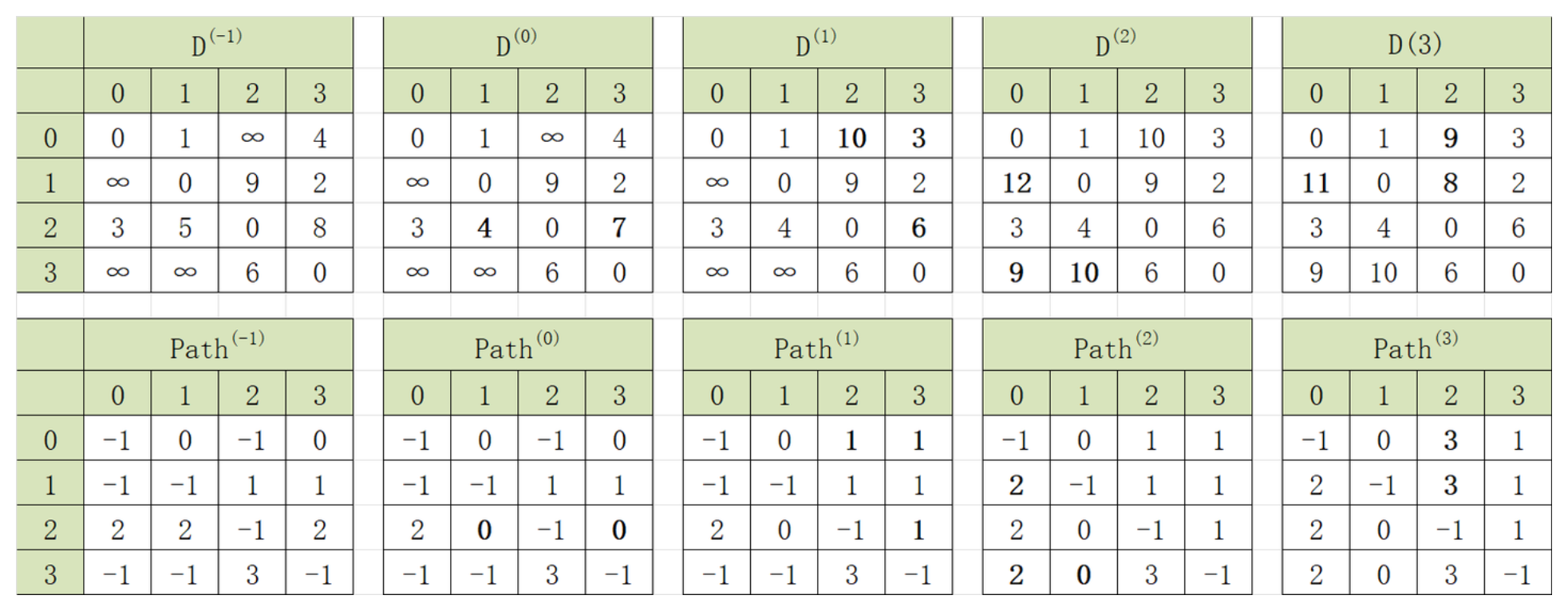
利用弗洛伊德算法,对下图所示的有向网G求解最短路径,,给出每一对顶点之间的最短路径及其路径长度在求解过程中的变化。
每一对顶点i和j之间的最短路径长度D[i][j]和最短路径Path[i][j]在求解过程中的变化,如下表:
3.4、算法分析
弗洛伊德算法的主循环共进行n次,每次执行的时间是O(n2),所以算法的时间复杂度是O(n3)。调用n次迪杰斯特拉算法的间复杂度也是O(n3),但弗洛伊德算法在形式上更加简单。
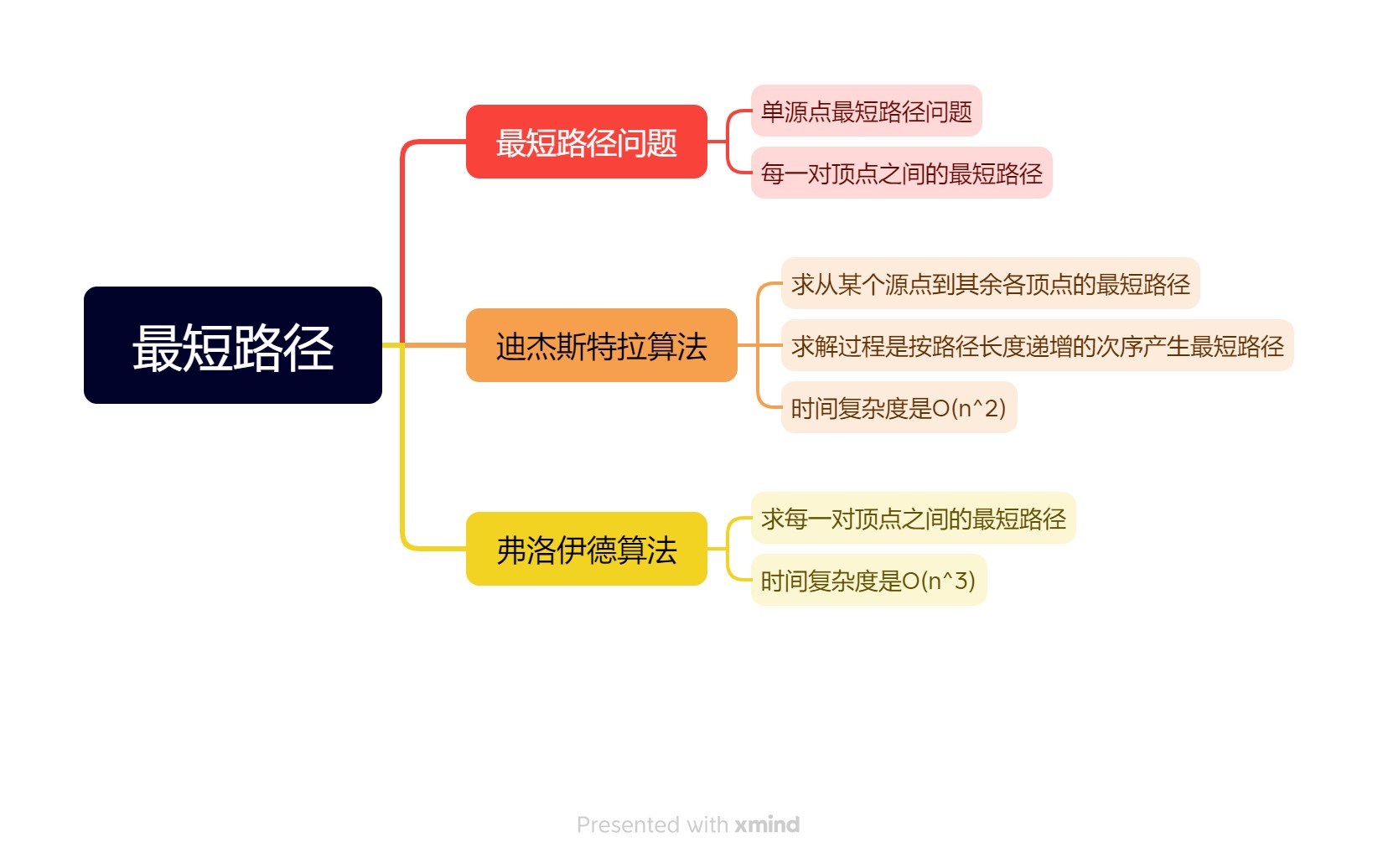
四、小结
最常见的最短路径问题有两种:一种是求从某个源点到其余各顶点的最短路径,另一种是求每一对顶点之间的最短路径。迪杰斯特拉算法,求从某个源点到其余各顶点的最短路径,求解过程是按路径长度递增的次序产生最短路径,时间复杂度是O(n2)。弗洛伊德算法,求每一对顶点之间的最短路径,时间复杂度是O(n3),从实现形式上来说,这种算法比以图中的每个顶点为源点调用n次迪杰斯特拉算法更为简洁。
五、参考
《数据结构(C语言版 第2版)》
《数据结构 自考02331》