数据库原理:关系模式的规范化理论
关系数据库系统设计的核心是关系型数据库设计,而关系型数据库设计的关键是设计关系型数据库的模式。关系型数据库模式的设计主要包括:数据库中应该包括多少个关系模式、每一个关系模式应该包括哪些属性、如何将这些相互关联的关系模式组建成一个完整的关系型数据库等。为构建满足业务需要、不存在异常问题的关系模式,需要在关系模式的规范化理论(简称“关系模式规范化”)的指导下进行关系型数据库的设计工作。
一、常见异常问题和规范化的内容
1.1、常见异常问题
如果不使用关系模式规范化理论,随意进行数据库设计,将导致哪些问题呢?下面以教学管理数据库为例分析这些问题。
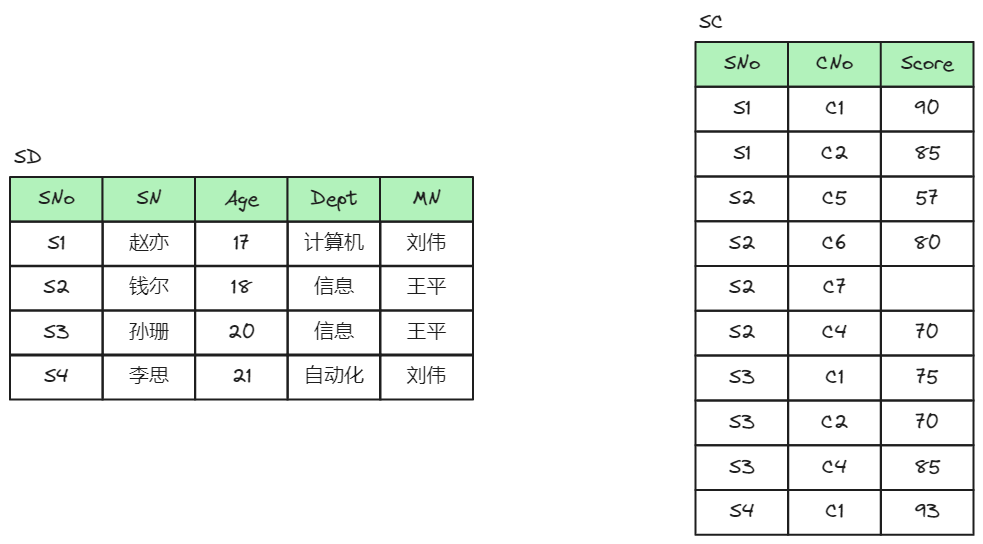
假设教学管理数据库的关系模式为SCD (SNo, SN, Age, Dept, MN, CNo, Scre),其中,SNo表示学生学号,SN表示学生姓名,Age表示学生年龄,Dept表示学生所在的系别,MN表示系主任姓名,CNo表示课程号,Score 表示成绩。根据实际情况,SCD中的这些数据具有如下语义规定:
- 一个系有若干名学生,但一名学生只属于一个系;
- 一个系只有一名系主任,但一名系主任可以同时兼任几个系的系主任;
- 一名学生可以选修多门课程,每门课程可被若干名学生选修;
- 每名学生学习的课程有一个成绩,但不一定立即给出。
在SCD中填入一部分实际数据,如下图所示。
| SNo | SN | Age | Dept | MN | CNo | Score |
|---|---|---|---|---|---|---|
| S1 | 赵亦 | 17 | 计算机 | 刘伟 | C1 | 90 |
| S1 | 赵亦 | 17 | 计算机 | 刘伟 | C2 | 85 |
| S2 | 钱尔 | 18 | 信息 | 王平 | C5 | 57 |
| S2 | 钱尔 | 18 | 信息 | 王平 | C6 | 80 |
| S2 | 钱尔 | 18 | 信息 | 王平 | C7 | |
| S2 | 钱尔 | 18 | 信息 | 王平 | C4 | 70 |
| S3 | 孙珊 | 20 | 信息 | 王平 | C1 | 75 |
| S3 | 孙珊 | 20 | 信息 | 王平 | C2 | 70 |
| S3 | 孙珊 | 20 | 信息 | 王平 | C4 | 85 |
| S4 | 李思 | 21 | 自动化 | 刘伟 | C1 | 93 |
在SCD中, (SNo, CNo)属性组合能唯一标识每一条记录,同时(SNo, CNo)满足属性数量最少的要求,所以(SNo, CNo)是关系模式SCD的主码。使用SCD建立教学管理数据库,会出现以下问题。
-
数据冗余。每个系名和系主任姓名的存储次数等于该系学生人数乘以每个学生选修的课程门数,同时学生的姓名、年龄也都要重复存储多次。数据的冗余度很大,浪费了存储空间。
-
插入异常。在SCD中,(SNo, CNo)是主码,当某个新系尚无学生时,SNo和CNo均无值,即使现实中系别存在系名和系主任,但根据实体完整性约束,数据插入要求主码不为空,所以无法插入现实世界中存在的系别信息。
同理,当新同学尚未选课时,主码(SNo, CNo)不能部分为空,也不能进行插入数据操作,出现插入异常问题。
-
删除异常。当某系学生全部毕业而没有招生时,要删除全部学生的记录,这时系名、系主任也随之删除,而现实中这个系可能依然存在,但在数据库中却无法找到该系的信息。
-
更新异常。如果某学生改名,则该学生的所有记录都要逐一修改SN的值;又如某系更换系主任,则属于该系的学生记录都要修改MN的内容,稍有不慎,就有可能漏改某些记录,这就会造成数据的不一致性,破坏了数据的完整性。
产生上述问题的原因是关系模式SCD中“包罗万象”,既包含了学生信息,又包含了学生选课和院系的信息,此时,称SCD为包含了所有数据的泛关系。泛关系的优势在于查询方便,不需要跨表连接,但在维护数据时,泛关系将描述各类内容的数据混杂在一起,导致上述异常的产生。
我们可通过关系模式的分解方法,将泛关系模式按其描述实体划分为子关系模式,解决各类异常问题。例如,泛关系模式SCD包含了学生、学生选课和课程实体的信息,按照实体分解SCD为学生关系S (SNo, SN, Age, Dept)、选课关系SC (SNo, CNo, Score)和系关系D (Dept, MN) 3个子关系模式。如下图,是分解后各子关系模式。
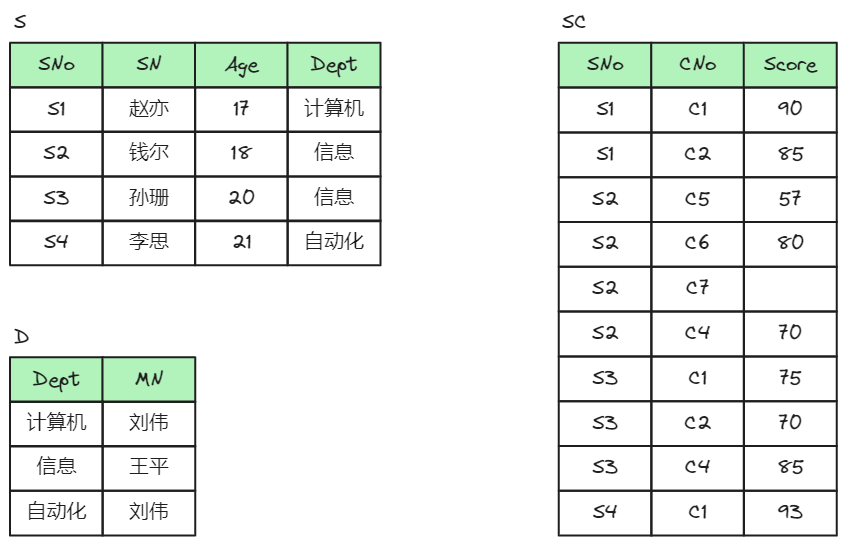
关系模式分解后,实现了学生信息、院系信息和学生选课信息的分离,即S中存储学生基本信息,与所选课程及系主任无关;D中存储院系的有关信息,与学生无关:SC中存储学生选课的信息,与学生及系别的有关信息无关。
与SCD相比,分解后的关系模式,数据的冗余度明显降低。分解后的关系模式解决了数据插入异常的问题:当新插入一个系时,只需要在关系D中添加一条记录即可;当某个学生尚未选课时,只需要在关系S中添加一条学生记录即可,而与选课关系无关。分解后的关系模式解决了删除异常的问题:当一个系的学生全部毕业时,只需要在S中删除该系的全部学生记录,而关系D中有关该系的信息仍然保留。分解后的关系模式解决了更新异常的问题:由于数据冗余度降低,数据没有重复存储,因此,分解后的关系模式不会引起更新异常。
经过上述分析,分解后的关系模式是规范的关系模式。由此可见,规范的关系模式应该具备以下4个条件:
- 尽可能少的数据冗余(允许外键冗余)。
- 没有插入异常。
- 没有删除异常
- 没有更新异常。
规范的关系模式并非最适合的设计方案,有时适度的数据冗余会提高查询效率。但是,一个最为适合的数据库设计方案,仍需在关系规范化理论的指导下,减少各类异常,设计符合业务、性能等多方面需求的折中设计方案。
1.2、规范化的内容
关系模式的规范化理论最早由关系数据库的创始人埃德加·考特于1970年在其文章《大型共享数据库数据的关系模型》中提出,后经许多专家学者的研究和发展,形成了一套关系数据库设计的理论。
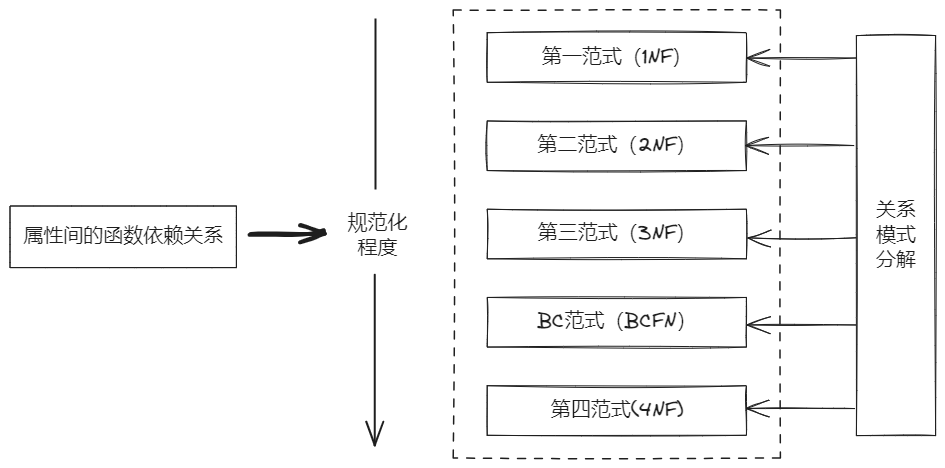
关系数据库的规范化理论以属性间的函数依赖关系为基础,按照范式(Normal Form,NF)级别定义了第一范式(First Normal Form, INF)、第二范式(Second Normal Form, 2NF)、第三范式(Third Normal Form, 3NF)、BC范式(BC Normal Form, BCNF)和第四范式(Fourth Normal Form, 4NF)等。数据库设计人员可根据范式级别,分析现有关系模式的规范化程度,并对不满足规范化级别的关系模式采取模式分解等方法提升关系模式的规范化程度。数据库规范化理论的主要内容如下图所示。
二、函数依赖
2.1、定义
关系规范化理论采用函数依赖描述数据项(属性)的依赖关系。函数依赖(FunctionalDependency, FD)是一种从语义上描述属性间依赖关系的手段。
例如,在关系模式SCD中,SNo与SN、Age和Dept之间都有一种逻辑依赖关系,即一个SNo只对应一个学生,而一个学生只能属于一个系,因此,当SNo的值确定之后,该学生的SN、Age、Dept的值也随之被确定了。
这类似于变量间的函数关系。设单值函数Y=F (X),自变量X的值可以唯一决定函数值Y。同理,我们可以说SNo的值唯一决定函数(SN, Age, Dept)的值,或者说(SN, Age, Dept)函数依赖于SNo。
函数依赖的形式化定义是:设关系模式R (U, F), U是属性全集,F是由U上函数依赖所构成的集合,X和Y是U的子集,如果对于R (U)的任意一个可能的关系r,对于X的每一个具体值,Y都有唯一的具体值与之对应,则称X决定函数Y,或Y函数依赖于X,记作XY。我们称X为决定因素,Y为依赖因素。当Y不函数依赖于X时,记作XY。当XY且YX时,记作XY。
下面我们通过关系模式SCD的例子来理解上述定义。根据U和F定义,可以得出:
以F中的最后一个函数依赖(SNo, CNo) Score为例。该函数依赖可理解为:一名学生拥有多门选修课程的成绩,即一个SNo与多个Score的值对应,因此,通过SNo 不能唯一地确定Score,即Score不函数依赖于SNo,从而有SNoScore;同理有CNoScore。但是Score可以被(SNo, CNo)所组成的属性集唯一地确定,所以该函数依赖可表示为(SNo,CNo) Score。
关于函数依赖,需要注意以下3项内容。
-
函数依赖是在业务定义下的语义概念。函数依赖实际上是对现实世界中事物性质间相关性的一种断言,当业务发生变化时,会导致抽象的函数依赖也发生变化。例如,对于关系模式S,当业务表明学生不存在重名的情况时,可以得到如下函数依赖:SNAge, SNDept。
-
函数依赖与属性之间的联系类型有关。在一个关系模式中,如果属性X与Y有1:1联系,则存在函数依赖XY和YX,即XY。例如,当学生无重名时,SNoSN。如果属性X与Y有n:1联系,则只存在函数依赖XY。例如,SNo与Age、Dept之间均为n:1联系,所以有SNoAge、SNoDept。如果属性X与Y有m:n联系,则X与Y之间不存在任何函数依赖关系。例如,一个学生可以选修多门课程,一门课程又可以被多个学生选修,所以SNo与CNo之间不存在函数依赖关系。因此,属性间的联系类型可用于分析和验证函数依赖关系。
-
函数依赖关系的存在与时间无关。函数依赖是指关系中的所有元组应该满足的约束条件,而不是指关系中某个或某些元组所满足的约束条件。关系中的元组增加、删除或更新后都不能破坏这种函数依赖。因此,我们必须根据语义来确定属性之间的函数依赖,而不能单凭某一时刻关系中的实际数据值来判断。例如,对于关系模式S,假设没有给出无重名的学生这种语义规定,则即使当前关系中没有重名的记录,也只能存在函数依赖SNoSN,而不能存在函数依赖SNSNo,因为如果新增加一个重名的学生,函数依赖SNSNo必然不成立,所以函数依赖关系的存在与时间无关。
2.2、分类
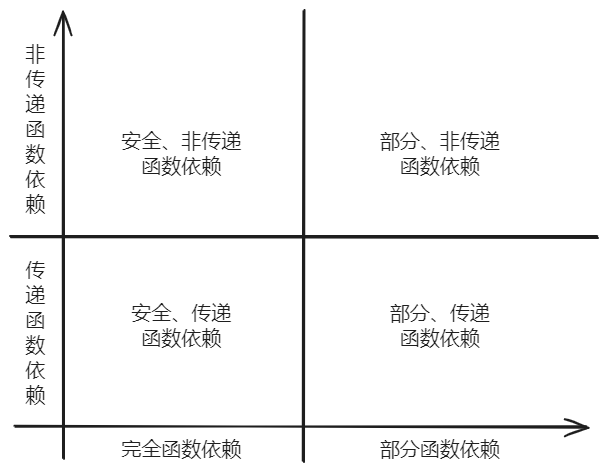
函数依赖可依据决定因素与被决定因素的关系,分为完全函数依赖(Full Functional Dependency)和部分函数依赖(Partial Functional Dependency)。函数依赖也可以根据其是否是通过传递性得到的,分为传递函数依赖(Transitive Functional Dependency)和非传递函数依赖。
完全函数依赖和部分函数依赖
设有关系模式R (U), U是属性全集,X和Y是U的子集,如果XY,并且对于X 的任何一个真子集X’,都有X’Y,则称Y完全函数依赖于X。如果对于X的某个真子集X’,有X’Y,则称Y部分函数依赖于X。
例如,在关系模式SCD中,对于函数依赖(SNo, CNo) Score,因SNoScore且CNoScore,所以有Score完全依赖于(SNo, CNo) 。而对于函数依赖SNoAge,如果在决定因素SNo中增加属性CNo,也能够唯一决定Age,所以Age部分函数依赖于(SNo, CNo) 。
这里需要注意的是,只有当决定因素X是组合属性时,讨论部分函数依赖才有意义,当决定因素是单属性时,则只可能是完全函数依赖。例如,在关系模式S (SNo, SN, Age, Dept)中,决定因素为单属性SNo,不存在部分函数依赖。
传递函数依赖和非传递函数依赖
设有关系模式R (U), U是属性全集,X、Y、Z是U的子集,若XY,但YX,而YZ ($Y \notin x 且 Z \notin Y \rightarrow\leftrightarrow$Y,这时称Z对X直接函数依赖,而不是传递函数依赖。这种情况即非传递函数依赖。
例如,在关系模式SCD中,学生学号确定后可以唯一确定学生所在院系,即SNoDept,但DeptSNo,同时,当院系确定后可唯一确定该院系的系主任,即DeptMN,因此,按照函数依赖的决定关系,上述函数依赖SNoDept和DeptMN满足传递性,即MN对SNo传递函数依赖。而在学生不存在重名的情况下,有SNoSN、SNSNo、SN→Dept,这时Dept对SNo是直接函数依赖,而不是传递函数依赖。
如下图,根据上述完全函数依赖、部分函数依赖、传递函数依赖和非传递函数依赖的定义,我们可将函数依赖为4类。在进行范式等级定义时, 如果定义要求函数依赖为完全函数依赖,则表明对函数依赖的传递性没有限制,既可以是完全、传递函数依赖,也可以是完全、非传递函数依赖。
2.3、案例分析
下面我们根据下表中所列举的数据结构和数据项,以商品库存表(关系)中部分关键属性为例,分析数据项(属性间)的函数依赖关系。
| 数据结构名称 | 数据项内容 |
|---|---|
| 用户信息 | 登录用户名、登录用户密码、电子邮箱等 |
| 登录凭证 | 用户名、登录时间等 |
| 商品库存 | 商品编号、名称、类别、生产厂家、入库时间、概述、库存量、供应商信息等 |
| 系统订单 | 订单编号、提交时间、订单总计、订单状态、销售商品、物流信息等 |
| 收货地址 | 联系人、性别、快递地址、手机、电子邮箱等 |
根据数据项之间的语义关系,商品编号能够唯一决定每件入库商品的基本信息、人库时间信息和供应商信息。因此,商品库存关系模式包含的函数依赖集合F如下所示。
根据上述函数依赖,当商品编号确定时,可以唯一确定该商品的名称、类别、生产厂家、概述、库存量和供应商信息等。因此,我们可进一步将函数依赖集合的右侧进行分解,将其分解为单属性的多个函数依赖。分解后的函数依赖集合F如下所示。
逐一分析上述函数依赖,其中,商品编号供应商信息的右侧不是单属性,按照属性原子化的要求,将供应商信息按业务台账的样例数据展开,即商品编号{供应商编号,供应商名称,供应商联系方式}。仔细分析该函数依赖发现,商品编号虽然能够唯一决定供应商编号,但商品编号与供应商名称和供应商联系方式为传递函数依赖关系,即满足业务语义的函数依赖为:商品编号→供应商编号,供应商编号→供应商名称,供应商编号→供应商联系方式。
通过上述分析,商品库存关系的函数依赖集合F如下所示。
通过上述方法,我们可以抽象出案例中其他关系模式的函数依赖,鉴于篇幅原因不再赘述。
三、范式
3.1、范式的提出
关系模式的分解是解决关系模式异常的主要手段,那么如何衡量分解后模式的好坏?利用范式理论可回答该问题。
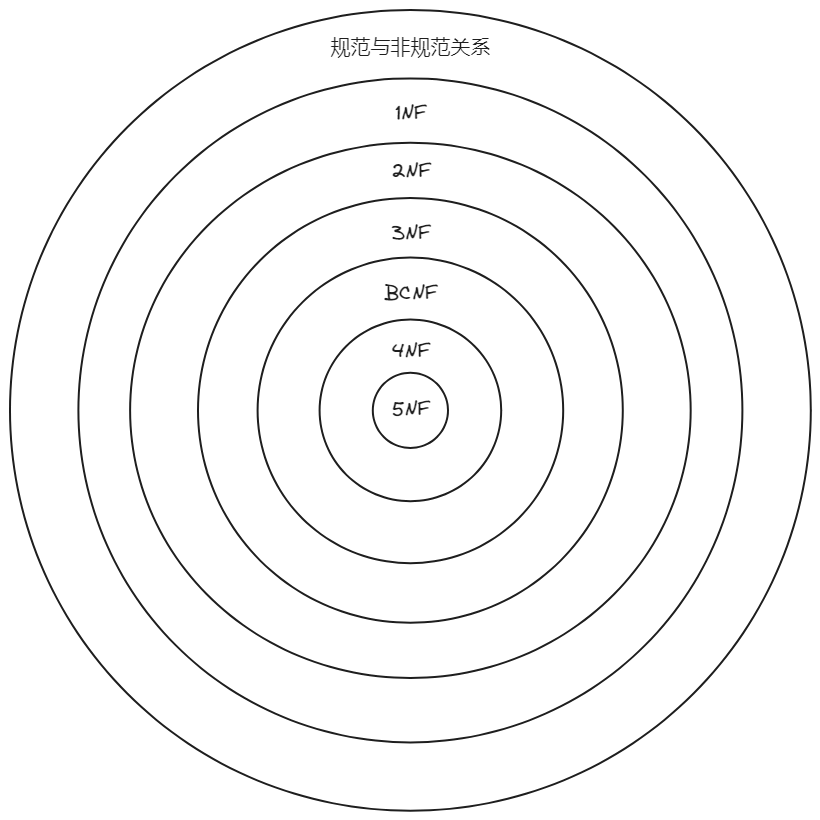
从1971年起,埃德加·考特相继提出了第一范式(1NF)、第二范式(2NF)和第三范式(3NF)。1974年,埃德加·考特和博伊斯(Boyce)共同提出了一个新的范式的概念,即BC范式(BCNF)。1976年,费金(Fagin)提出了第四范式(4NF)。此后,人们又提出了第五范式(5NF)。各个范式之间的联系可以表示为,如下图所示。
3.2、范式的级别
3.2.1、第一范式
3.2.1.1、定义
第一范式(1NF)是关系模式的最基本规范形式,它要求关系模式中每个属性都是不可再分的原子项。
第一范式的标准定义是,如果关系模式R所有的属性均为原子属性,即每个属性都是不可再分的,则称R属于第一范式,记作。
1NF是关系模式应具备的最基本条件,只有满足1NF的关系模式才称为规范化关系模式,1NF的关系模式是后续更高级别规范化的基础,这也是它被称为“第一”的原因。
3.2.1.2、规范化方法
在设计数据库时,第一范式的实施步骤是将关系模式中所有的属性原子化。
这里需要注意的是,我们强调1NF是关系数据库规范化设计的基础,目的是让初学者在开展数据库设计时,确保属性尽量原子化,培养关系规范化设计的基本素养。但是在实际进行数据库设计时,综合考虑查询效率等原因,我们会让部分属性呈现非原子化的情况,如商品的物流信息等。在实际进行数据库设计时,还是应尽量遵守1NF的要求,仅当具备丰富的数据库经验后,再考虑属性原子化的成本问题。
3.2.1.3、缺点
一个关系模式仅仅属于第一范式是不够的。前面给出的泛关系模式SCD属于第一范式,但它存在数据冗余、插入异常、删除异常和更新异常等问题。
下面我们来分析泛关系模式SCD中的函数依赖关系。
为方便分析,我们使用函数依赖图整体表示SCD中的函数依赖关系。在函数依赖图中,使用矩形框表示属性,使用箭头表示函数依赖的决定关系,箭头上标注函数依赖的类型,如下图所示。
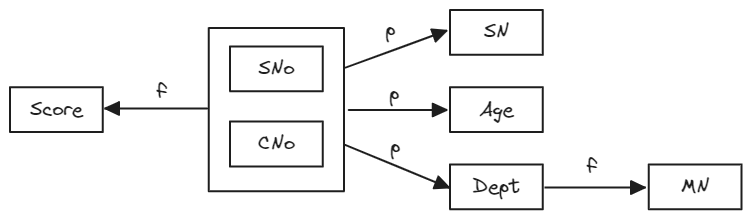
从该图可以看出,泛关系模式SCD中既存在完全函数依赖,又存在部分函数依赖和传递函数依赖。由于关系模式中存在各类函数依赖,导致数据操作中出现了种种问题。为解决这些问题,我们还需要进一步分解关系模式,减少过于复杂的函数依赖关系。
3.2.2、第二范式
3.2.2.1、定义
第二范式(2NF)是在第一范式基础上构建的范式。
第二范式的标准定义是,如果关系模式,且每个非主属性都完全函数依赖于R的主码,则称R属于第二范式,记作。如果数据库模式中每个关系模式都是2NF,则称这个数据库模式为2NF的数据库模式。
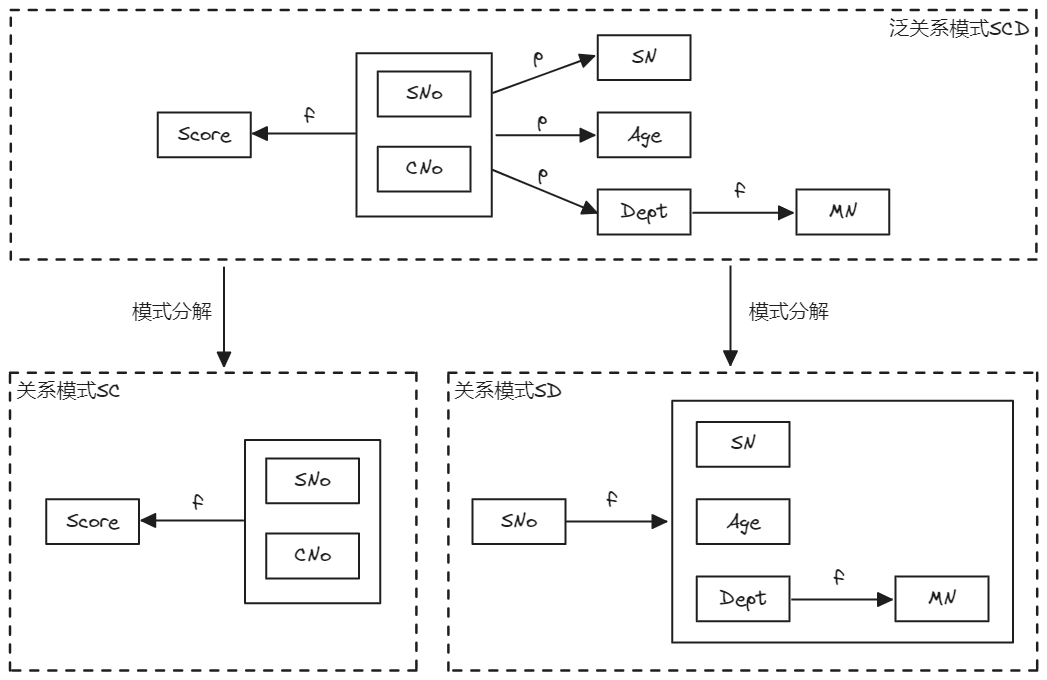
在泛关系模式SCD中,SNo、CNo为主属性,Age、Dept、SN、MN和Score均为非主属性,根据前面的进行分析,存在非主属性对主码的部分函数依赖,所以SCDE2NF。如下图,将SCD分解为2个关系模式SD和SC。在SD中,主码为SNo,主码是单属性,不可能存在部分函数依赖。在SC中, (SNo, CNo) Score。分解后的关系模式SD和SC消除了非主属性对主码的部分函数依赖,SD和SC均属于2NF。
按照2NF的定义,当关系模式不存在非主属性时,关系模式属于2NF。例如,在关系模式TC (T, C)中,一个教师可以讲授多门课程,一门课程可以被多个教师讲授,T和C两个属性的组合(T, C)是主码,T、C都是主属性,而没有非主属性,所以也就不可能存在非主属性对主码的部分函数依赖,因此。
经以上分析,我们可以得到以下两个结论。
-
从1NF关系中消除非主属性对主码的部分函数依赖,是获得2NF的关键步骤。
-
如果R的主码为单属性,或R的全体属性均为主属性,则。
3.2.2.2、规范化方法
基于关系模式“一事一地”原则,从满足第一范式的关系模式中,将部分函数依赖的决定属性和被决定属性提取出来,形成不存在部分函数依赖的子关系模式集合,分解后的每一个关系模式只描述一个实体或者实体间的联系。下面以关系模式SCD为例说明第二范式的规范化过程。
将SCD (SNo, SN, Age, Dept, MN, CNo, Score)规范为2NF。由(SNo, CNo) (SN, Age, Dept, MN},(SNo, CNo) Score,可以判断,{SN, Age,Dept, MN}部分函数依赖于(SNo, CNo),不满足第二范式要求。将该部分函数依赖中的决定因素SNo和被决定因素提取出来,得到SNo {SN, Age, Dept, MN},从而形成两个关系模式SD和SC,如下图所示。
按照“一事一地”原则,SNo {SN, Age, Dept, MN}描述了关系模式SD,(SNo,CNo) Score描述了关系模式SC。
经上述关系模式分解后,SD的主码为SNo, SC的主码为(SNo, CNo),其他出现在两个关系模式中的属性均为非主属性,且非主属性在对应的关系模式中对主码均是完全函数依赖。因此,$SD \in 2NF, : SC \in 2NF $。
第一范式的关系模式经过投影分解转换成第二范式的关系模式后,消除了一些数据冗余。分析上图中SD和SC中的数据,可以看出,它们的存储冗余度比关系模式SCD有了较大幅度的降低。学生的姓名、年龄不需要重复存储多次。这样便可在一定程度上避免数据更新所造成的数据不一致性问题。同时,由于把学生的基本信息与选课信息分开存储,则学生基本信息因没有选课而不能插入的问题得到了解决,插入异常问题得到了改善。同样,如果某个学生不再选修C1课程,只在选课关系SC中删除该学生选修C1的记录即可,SD中有关该学生的信息不受任何影响,这解决了部分删除异常问题。因此,分解后的关系模式SD和SC在性能上比SCD有了显著提高
3.2.2.3、缺点
第二范式的关系模式解决了第一范式中存在的一些问题,但在进行数据操作时,仍然存在下面的一些问题。以分解后满足第二范式的关系模式SD为例,分析如下。
-
数据冗余。如每个系名和系主任的名字存储的次数等于该系的学生人数。
-
插人异常。如当一个新系没有招生时,有关该系的信息无法插入。
-
删除异常。如某系学生全部毕业而没有招生时删除全部学生的记录也随之删除了该系的有关信息。
-
更新异常。如更换系主任时,仍需改动较多的学生记录。
存在上述问题的原因是,在SD中存在非主属性对主码的传递函数依赖。分析SD中的函数依赖发现,在函数依赖SNo MN中,非主属性MN对主码SNo传递函数依赖,导致出现了数据冗余、插入异常、删除异常、更新异常等问题。为此,我们还需要对关系模式SD进一步进行模式分解,消除传递函数依赖所产生的异常问题。
3.2.3、第三范式
3.2.3.1、定义
第三范式(3NF)是在第二范式的基础上构建的范式。
第三范式的标准定义是,如果关系模式,且每个非主属性都非传递函数依赖于R的主码,则称R属于第三范式,记作。
前面由关系模式SCD分解而得到的SD (SNo, SN, Age, Dept, MN)和SC (SNo, CNo, Score),它们都属于第二范式。在SC中,主码为(SNo, CNo),非主属性为Score,函数依赖为(SNo, CNo) Score,非主属性Score非传递函数依赖于主码(SNo, CNo),因此,。但在SD中,主码为SNo,非主属性Dept和MN与主码SNo间存在函数依赖SNoDept和DeptMN,即SNo MN。由此可见,非主属性MN与主码SNo间存在传递函数依赖,所以。
3.2.3.2、规范化方法
将第二范式关系模式中存在的传递函数依赖提取出来,确保每个关系模式不存在非主属性对主码的传递函数依赖,然后遵循“一事一地”原则,让一个关系只描述一个实体或者实体间的联系。下面以关系模式SD为例说明第三范式的规范化过程。
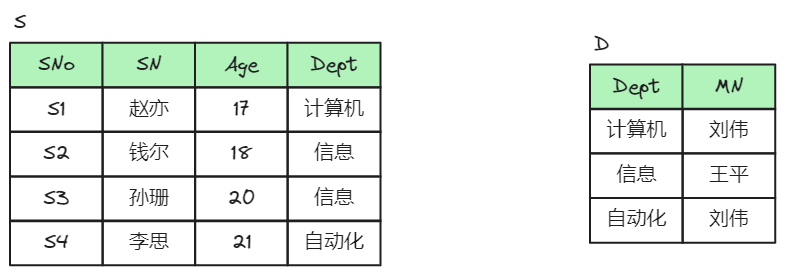
通过语义分析可知,关系模式SD中包含的函数依赖SNo MN不满足第三范式要求,需将传递、函数依赖进行拆分,拆分为完全、非传递函数依赖,即SNo Dept,Dept MN。结合“一事一地”原则,关系模式SD中描述了两个实体,其中一个是学生实体,其属性有SNo、SN、 Age、Dept;另一个是系别的实体,其属性有Dept和MN。按照分解后获得的函数依赖Dept MN,分解SD形成两个关系模式,分别是学生关系模式S (SNo, SN, Age, Dept)和系别关系模式D (Dept, MN),如下图所示。
从该图可以看出,分解为第三范式后,函数依赖关系变得更加简单,既没有非主属性对主码的部分函数依赖,也没有非主属性对主码的传递函数依赖,解决了第二范式中存在的问题。
-
数据冗余降低了。如系主任的姓名存储的次数与该系的学生人数无关,只在D中存储一次。
-
不存在插入异常。如当一个新系没有学生时,该系的信息可以直接插入D中,而与S无关。
-
不存在删除异常。当要删除某系的全部学生而仍然保留该系的有关信息时,可以只删除S中的相关学生记录,而不影响D中的数据。
-
不存在更新异常。如更换系主任时,只需要修改D中一个相应元组的MN属性值,不会出现数据不一致性问题。
3.2.3.3、缺点
在将泛关系模式SCD规范到第三范式后,泛关系模式SCD所存在的数据冗余、插入异常、删除异常和更新异常问题已经全部消失。但第二范式和第三范式均针对非主属性和主属性之间的函数依赖关系,并未考虑主属性与主码的函数依赖关系或主属性之间的函数依赖关系。如果发生了这种函数依赖,仍有可能存在数据冗余、插入异常、删除异常和修改异常。
例如,设有关系模式SNC (SNo, SN, CNo, Score),其中SNo代表学号,SN代表学生姓名并假设没有重名,CNo代表课程号,Score代表成绩。可以判定,SNC有两个候选码(SNo, CNo)和(SN, CNo),其函数依赖如下。
在SNC中,主属性为{SNo, SN, CNo},非主属性为Score,如果选择(SNo, CNo)为主码,则唯一的非主属性Score对主码不存在部分函数依赖,也不存在传递函数依赖,所以。但是,因为SNoSN,存在主属性对主码的部分函数依赖(SNo, CNo) SN,造成SNC中存在较大的数据冗余,即学生姓名的出现次数等于该学生所选的课程数,同时,当更改某个学生的姓名时,必须搜索出该姓名的每个学生记录,并对其姓名逐一修改,这样容易造成数据不一致性问题。
为解决第三范式中主属性与主码之间的部分函数依赖问题,需消除第三范式中存在的主属性对主码的函数依赖关系,将第三范式进一步规范化到BCNF。
实际上,BCNF只出现在主码为属性集的情况下。在关系模式中,当出现主属性与主码的函数依赖关系时,可以将该函数依赖涉及的主属性从现有关系模式中分解出来,构建新的关系模式,如将SNC分解为关系模式SS (SNo, SN) (用于描述学生实体)和关系模式SC (SNo, CNo, Score) (用于描述学生与课程的联系),分解后的关系模式不存在主属性对主码的部分函数依赖。
有关BCNF的内容,读者可以参阅相关资料,这里不进行详细讲解。
3.3、关系模式规范化的过程
一个低一级范式的关系模式,通过模式分解转化为若干个高一级范式的关系模式的集合,这种分解过程称为关系模式的规范化。关系模式的规范化过程就是逐步消除关系模式中不合适的函数依赖的过程。
在满足属性原子化的基础上,规范化的基本原则就是遵循“一事一地”的原则,即一个关系模式只描述一个实体或者实体间的联系。若多于一个实体,就把它“分离”出来。
在满足属性原子化的基础上,规范化的步骤就是对原关系进行模式分解,消除非主属性与主属性之间的部分函数依赖和传递函数依赖,消除主属性与主码之间的部分函数依赖。如下是关系模式规范化的步骤图。
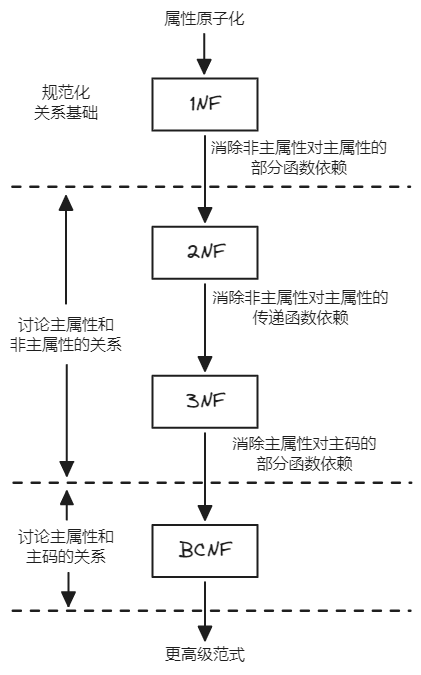
关系模式规范化的基本步骤为:
-
检查泛关系模式中各属性,将不满足原子性要求的属性分解为原子属性,形成满足1NF的关系模式。
-
分析所有满足1NF关系模式的主码与主属性,查验每个关系模式中非主属性和主码的函数依赖关系,如果存在非主属性对主码的部分函数依赖,则分解该关系模式,消除关系模式中非主属性对主码的部分函数依赖,将1NF关系模式转换成2NF关系模式。
-
分析所有满足2NF的关系模式,查验每个关系模式中非主属性和主码的函数依赖关系,如果存在非主属性对主码的传递函数依赖,则分解该关系模式,消除关系模式中非主属性对主码的传递函数依赖,将2NF关系模式转换成3NF关系模式。
-
分析所有满足3NF的关系模式,查验每个关系模式中主属性和主码的函数依赖关系,如果存在主属性对主码的部分函数依赖,则分解该关系模式,消除关系模式中主属性对主码的部分函数依赖,将3NF关系模式转换成BCNF关系模式。
一般情况下,没有数据冗余、插入异常、更新异常和删除异常的数据库设计可称为合适的数据库设计。但是进行关系模式分解时,要综合考虑分解后关系模式的查询效率和存储代价,视实际情况而定。对于那些只需查找而不要求插入、删除等操作的数据库系统,不宜过度分解,否则当对系统进行整体查询时,需要更多的表连接操作,这有可能得不偿失。
在实际应用中,最有价值的是3NF和BCNF,在进行关系模式的规范化时,通常分解到3NF 就足够了。
3.4、关系模式规范化的要求
关系模式的规范化过程是通过对关系模式的分解来实现的,但是模式分解的方式不是唯一的,不同的分解会得到不同的关系模式。在这些分解方法中,只有能够保证分解后的关系模式与原关系模式等价的方法才是有意义的。所谓等价的关系模式,即模式分解过程保持分解前后的函数依赖和具有无损连接分解。
无损连接分解是指分解后的关系模式经过自然连接后形成的关系模式,与分解前的关系模式具有相同的信息量。对前面的关系模式SD和SC进行分析发现,两个关系模式自然连接后与分解前的关系模式SCD表达的信息量相同,即分解没有丢失任何信息,满足分解的无损连接要求。
保持函数依赖是指分解后关系模式的所有函数依赖与分解前关系模式的函数依赖等价。这里的等价性需要依赖于规范化理论的Armstrong公理。Armstrong公理内容较为复杂,我们可以以更为直观的方式理解:不要将一个完全、非传递的函数依赖中出现的决定因素和被决定因素分解到不同关系模式中,例如不要把SCD中决定因素SNo和被决定因素SN、Age等分解到不同的关系模式中,这样就可保证分解后的关系模式的函数依赖与分解前关系模式的函数依赖等价。
需要注意的是,无损连接性和函数依赖保持性是两个相互独立的标准。具有无损连接性的分解不一定具有函数依赖保持性。同样,具有函数依赖保持性的分解也不一定具有无损连接性。
四、小结
本章讲述了关系操作的常见异常和关系规范化主要内容;介绍了函数依赖的定义和类型;数重点讲解了第一范式、第二范式、第三范式这3类主流范式的定义和关系,以及各类范式转化的原则、步骤和注意事项。
不合理的关系模式主要存在数据冗余、插人异常、删除异常和更新异常。发生上述异常的原因是关系模式中描述了过多的事物,我们可采田关系模式分解方法,将不合理的关系模式转换为规范的关系模式。
函数依赖为关系模式分解提供分析工具,它从关系模式所表示的业务语义出发,以形式化方式展示各属性之间的逻辑语义依赖关系。常见的函数依赖包括完全函数依赖、部分函数依赖和传递函数依赖。
基于“一事一地”的原则,借助函数依赖和关系规范化理论,我们可将关系模式分解为满足第一范式、第二范式、第三范式和BCNF要求的关系模式。关系模式分解需保证分解过程既具有无损连接性又保持函数依赖,通常分解到第三范式或BCNF就足够了。